Fraud Detection Project
"Turn data into a shield—detecting and stopping fraudulent transactions before they even happen!"

Project Objectives
The main goal of this project was to explore the selected dataset using tools such as SQL Server and Python to treat the data and create Machine Learning models, finalizing it with a dashboard built in PowerBI. The project objectives are as follow:
- Analyse the dataset and try to identify which factors have more impact in the fraudulent transactions.
- Can I train a Machine Learning model to predict fraudulent transactions?
- Provide clear insights on how to prevent fraud.
Questions (KPIs)
- When is more likely to receive a fraudulent transaction? (Day / Month)
- The time of the day makes difference in the fraudulent transactions received?
- Are there any Merchants receiving more fraudulent transactions than others?
- The Category of the transaction impacts the fraudulent transactions received?
- Does the dataset have many fraudulent transactions?
- The AccountBalance influences the fraudulent transactions?
Process
- Merged all 10 csv files into a table in SQL Server.
- Created new variables to add value to the dataset(table) using SQL.
- Verified data for any duplicates and missing values (Python).
- Made sure all data is consistant in terms of data types, data format and values.
- Created visual representation for some variables.
- Did some Statistical Analysis using T-Test technique.
- Trained 2 ML models (Random Forest Classifier & XGBC Classifier).
- Did an oversampling to the data as the dataset was too imbalanced.
- As the previous ones were inconclusive, even with the oversampling, decided to train another one (One-Class SVM).
Dashboard
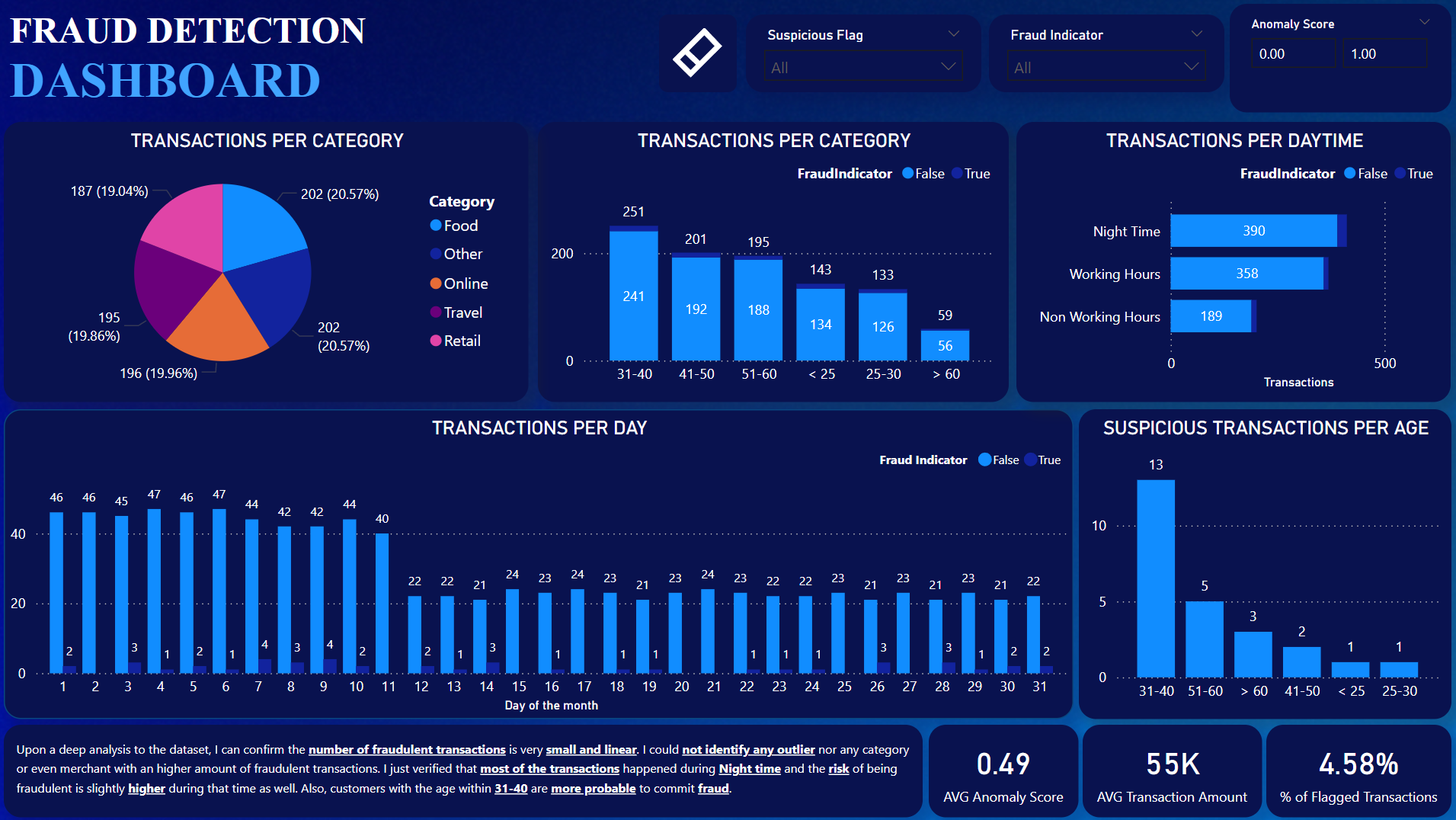
Project Insights
- The dataset has a total of 982 transactions.
- With the columns created, the dataset has a total of 17 columns.
- Only 45 transactions were flagged as fraudulent transactions(4.58%).
- Had to remove 18 transactions has the transaction timestamp happend after the LastLogin, which is impossible.
- 364 Customers did not have any transaction associated, so they were removed as my focus for the project was in the fraudulent transactions.
- Night Time had the most transactions placed and the time with more fraudulent transactions as well.
- All the 45 Fraudulent transactions happened in a different Merchant, this means no Merchant had more than 1 fraudulent transaction.
- The ransactions were evenly distributed by the 5 Categories (Between 19.05% and 20.57%).
- The Transaction Amount is also evenly distributed per Categories.
Final Conclusion
The fact the Dataset had only 4.58% of fraudulent transactions made it really difficult to work with. All the machine learning models failed to identify the minority class (Fraudulent Transactions) even after I did an Oversampling using SMOTE. Even if I tried other algorithms and oversample techniques the results would remain pretty similar, therefore I decided to end my analysis to this dataset. In a real life case, the solution would be to keep gathering transaction details to feed the dataset. Then in a later stage do the analysis again.